
Why “Replies” Matter for Workflow Reliability
Workflow automation depends on more than triggering the right action. A system can send an event, move to the next step, and appear to function correctly, even when the intended action never actually happens.
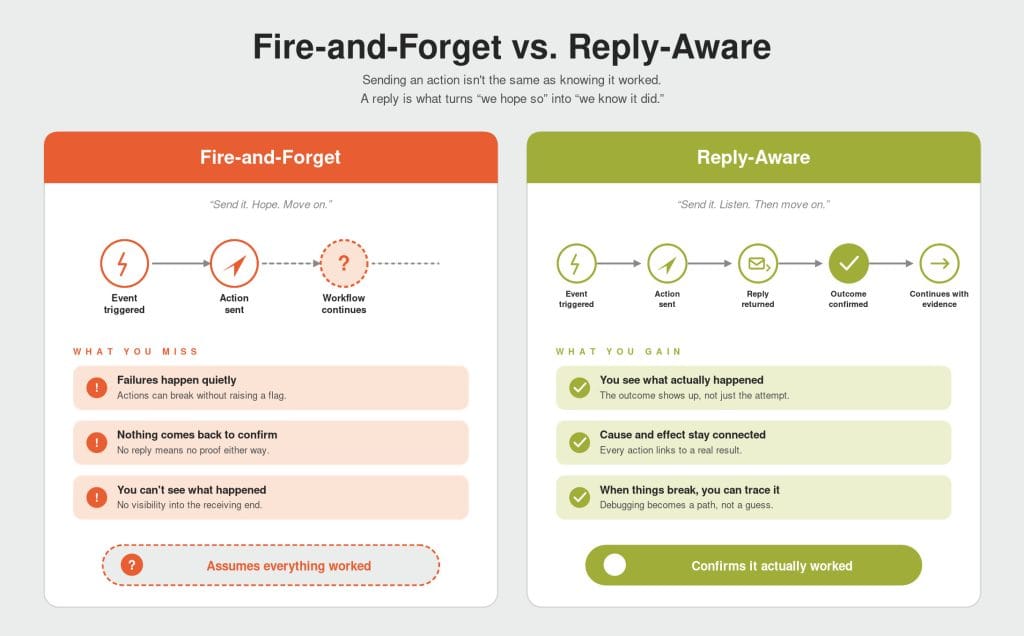
That is the hidden risk behind many “fire-and-forget” workflow models. They treat execution as proof of success. If the event fired, the workflow assumes the action succeeded and proceeds. But in real-world automation systems, especially across security, operations, and critical infrastructure environments, that assumption can create serious blind spots.
As Aakanksha Katarni put it from a QA perspective:
“Execution just means it ran. Confirmation means it actually worked.”
That distinction is at the heart of workflow reliability. A workflow that cannot verify outcomes is not fully observable. It is only assuming success. And in high-stakes environments, the gap between “it ran” and “it worked” can become the difference between a reliable workflow and a silent failure.
What a Silent Workflow Failure Looks Like in Practice
Imagine a workflow that sends an alarm event.
The event fires. The workflow moves on. On the surface, everything appears to have executed correctly. But the receiving system never actually raises the alarm.
There is no visible system crash. No obvious workflow breakdown. No immediate signal that the action failed. The event went somewhere, the workflow continued, and the system appeared healthy. But the outcome that mattered disappeared.
That is what makes silent workflow failures so difficult to manage. They do not always look like failures. They can look like normal operation.
From Aakanksha’s perspective, that is not just a logging problem. If an alarm event is sent and everyone assumes it worked, but the alarm never fires, the issue has already moved beyond technical inconvenience. It has become an operational problem.
The workflow did not stop. The outcome disappeared.
The Real Problem Isn’t Execution, It’s Assumption
Traditional automation systems often focus on whether an event was triggered. But triggering an event only proves that the workflow attempted an action. It does not prove that the action succeeded.
That distinction matters. “Did the event fire?” is not the same question as “Did the system do what we needed?”
In a fire-and-forget model, the workflow may send an event and continue forward without receiving confirmation from the system that was supposed to act on it. If something fails along the way, the failure can disappear completely. There may be no reply, no visible alert, and no reliable way to know that the intended outcome never occurred.
For QA teams, that kind of uncertainty changes the entire debugging process. If behavior seems inconsistent, the right instinct is not to assume the tester misunderstood the system. The inconsistency may be real. The implementation may be incomplete. The workflow may be doing exactly what it was designed to do while still failing to produce the outcome the operator expected.
A system that cannot confirm outcomes forces teams to trust assumptions instead of evidence.
The Root Cause: Disconnected Workflow Feedback
In fire-and-forget workflows, the issue is often not that an action cannot produce a success or failure state. The issue is that the feedback may be disconnected from the original workflow context.
An event triggers an action. The workflow continues. Any success or failure state may remain inside the receiving system or inside the automation tool that handled that specific step. Downstream tools may not see the result. The original workflow loses the causal connection between the event that started the action and the outcome that followed.
That creates several problems at once.
The workflow looks complete. The action may have failed. The failure may not be tied back to the original event. Engineers are left cross-referencing logs, reconstructing timelines, and trying to infer what happened from disconnected fragments.
This is one of the core limitations Teldio Fabric is designed to address. The platform is designed as a move away from legacy “fire-and-forget” triggers toward reply-aware workflows that support observable, reliable automation.
When feedback is disconnected from the original event, causality becomes harder to prove.
What Event Replies Change in Teldio Fabric
Teldio Fabric’s Event Reply model changes the workflow structure by keeping outcome feedback inside the original event lifecycle.
An Event Reply is not a separate log entry. It is not a disconnected follow-up event. It is the module responding back through the same event that triggered it. That reply can indicate whether the action succeeded or failed and, in future use cases, may also carry richer data returned by the system.
The important shift is causality.
The reply preserves the relationship among the event that triggered the action, the module that acted on it, and the outcome that was returned. Instead of treating the workflow as a chain of disconnected actions, Teldio Fabric keeps the response attached to the event that caused it.
Aakanksha described this as essential to debugging. If a reply came back as a separate event, there would be no reliable way to connect it to the trigger. Keeping the reply within the original event maintains the causal chain, allowing Teldio Fabric’s Behavior Introspection to identify the specific step where something failed.
Teldio Fabric does not just ask whether an event fired. It gives the workflow a way to understand what happened next.
Why Behavior Introspection Needs Replies
Behavior Introspection is the part of Teldio Fabric that shows what happened inside a behavior and where something went wrong.
Without replies, introspection can confirm that a workflow step ran. But that only answers part of the question. It shows execution, not outcome.
With replies, Behavior Introspection can show that something ran, failed, and returned a specific result. It turns a vague sense that “something failed somewhere” into a traceable answer: this step failed, for this reason, inside this event’s lifecycle.
As Aakanksha explained:
“With replies, it can tell you something ran and failed, and point to the exact step where it broke.”
That is what makes reply-aware workflows so important. Replies give Behavior Introspection the evidence it needs to make workflow behavior observable. They transform workflow debugging from a broad investigation into a targeted diagnosis.
Behavior Introspection turns workflow failure from a vague suspicion into a traceable answer.
The Debugging Shift: From Guesswork to Evidence

The practical value of replies becomes clearest during debugging.
Before replies, failures could be invisible or difficult to isolate. Teams might need to piece together separate log entries without a clear connection to the event that caused them. A workflow may appear to run successfully while the intended action fails somewhere within the process.
For QA, that raises an uncomfortable question: did the test fail, the configuration fail, or the system fail?
Aakanksha described the change clearly:
“Now you can actually point to the exact step and say that’s where it fell apart.”
That changes more than the speed of debugging. It changes the quality of the work. Bug reports become sharper. Test cases become more intentional. Teams stop wasting time chasing disconnected symptoms and can focus on the specific step where the behavior broke.
This is also where the QA mindset behind the feature becomes visible. The value is not simply that Teldio Fabric provides another technical capability. The value is that it supports a more disciplined way of understanding system behavior.
Do not assume. Test what is visible. Follow the evidence. Draw conclusions only from what can be verified.
That is the difference between a workflow that appears reliable and one that can be proven reliable.
Reply-aware workflows do not just make debugging faster. They make debugging more honest.
Why Logs Alone Are Not Enough
Logs are useful, but they are not the same as replies.
A log can show that something happened somewhere in the system. But depending on how the system is designed, that log may exist outside the workflow context. It may require interpretation. It may need to be cross-referenced with other records. It may not clearly connect the trigger, the action, and the outcome.
A reply does something different. It shows what happened in relation to the event that caused it.
That distinction matters because workflow reliability depends on context. It is not enough to know that a system produced an activity. Engineers need to know whether that activity was the intended result of a specific workflow step.
Logs record activity. Replies confirm outcome.
A reply gives the workflow context that a disconnected log cannot always provide.
Not Every Action Can Reply, and That Matters
A reliable workflow architecture also needs to be honest about its limits.
Not every system can provide confirmation. Some actions are one-way by nature. A contact closure may fire without any handshake or acknowledgment from the receiving end. Some systems simply do not send confirmation back.
Aakanksha’s view is practical: when no reply is possible, engineers should treat no reply as expected behavior rather than a system failure. The important thing is understanding where confirmation is possible, where it is not, and how the workflow should be designed around that boundary.
This acknowledgment strengthens the engineering argument. Observability is not about pretending every action can confirm itself. It is about making confirmation explicit wherever the system allows it.
Reliable workflow design requires knowing where certainty ends.
What Clean Workflow Design Looks Like
Clean workflow design is not just about whether the system runs. It is about whether the system can explain itself.
Aakanksha defines a clean system through cause and effect:
“A clean system lets you trace what happened, why it happened, and whether it actually worked.”
When those things are connected, debugging becomes more straightforward. Trust in the system builds naturally. Workflows behave more predictably because teams are not working from incomplete information.
When those things are disconnected, teams are left hoping the workflow behaves as it appeared to.
That is the deeper engineering principle behind Event Replies and Behavior Introspection. Reliable systems are built through verification, not assumption. They preserve causality. They make outcomes visible. They allow engineers, QA teams, and operators to understand not only that something happened, but why it happened and whether it worked.
A clean workflow is not just one that runs. It is one that can explain itself.
Why This Matters for Security and Critical Workflows
In security and operational environments, workflow failure is not abstract.
A failed workflow can affect alarm response, access control actions, camera or VMS workflows, radio notifications, escalation paths, and operator awareness. In these environments, an automation step that silently fails can leave teams believing a response occurred when it did not.
The risk is not always dramatic. Sometimes the system simply moves on as if everything worked.
That is what makes confirmation so important. Security workflow automation depends on more than sending events between systems. It depends on knowing whether those systems responded as expected.
In critical workflows, an unconfirmed action can become an invisible risk.
Teldio Fabric’s reply-aware architecture supports more reliable, observable automation by helping teams understand not only what ran, but what actually happened.
From Fire-and-Forget to Observable Automation
Modern workflow systems need to move beyond simple event execution.
Reliable automation requires confirmation, traceability, causality, observable outcomes, and deterministic debugging. The more systems a workflow touches, the more important those qualities become.
Teldio Fabric is built around the idea that automation should be inspectable, not assumed. Event Replies and Behavior Introspection work together to make workflows easier to understand, test, and trust.
The contrast is simple: Before the event fired, the system assumed success. After the event fires, a reply returns, and the outcome becomes visible.
That shift matters because workflow reliability is not only about building automations that run. It is about building automations that can be observed, tested, and trusted under real-world conditions.
The future of workflow reliability is not just automation. It is observable automation.
Building More Reliable Workflow Architectures
The same risks that appear in simple workflows become more significant across complex integration environments.
Security operations, industrial automation, critical communications, access control, video workflows, enterprise alerting, and multi-system event orchestration all depend on actions moving correctly between systems. As those environments become more connected, the cost of assuming success grows.
Resilience comes from anticipating silent failure, preserving workflow context, designing around systems that cannot reply, and making failures visible at the step level.
Reliable workflows are not built by assuming every step succeeded. They are built by proving what happened at each step.
Talk to Teldio About Observable Workflow Automation
Teldio Fabric helps organizations move beyond fire-and-forget automation with reply-aware workflows, Behavior Introspection, and clearer visibility into system outcomes.
Learn how Teldio Fabric enables observable, reliable workflow automation, or speak with Teldio about building more reliable automation systems for security, operations, and critical environments.